ToFind(同源码网站收集工具)
https://github.com/XiaoMMing9/ToFind
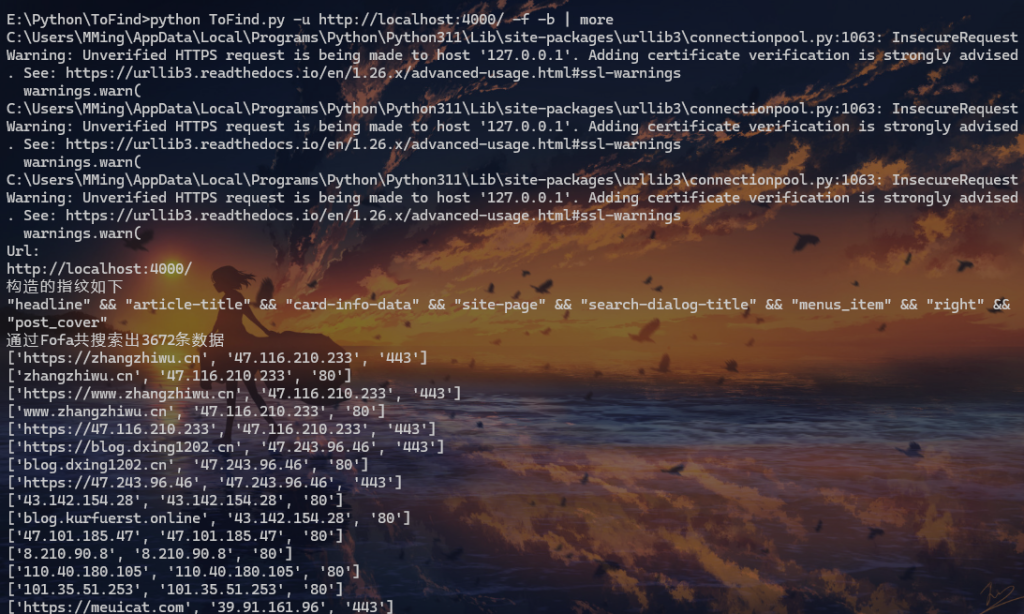
发现网站特征指纹,可以通过Fofa搜寻同源网站
python代码
import base64
import requests
from bs4 import BeautifulSoup
import re
import random
import argparse
import json
import pandas as pd
import os
from openpyxl import Workbook
from openpyxl.utils.dataframe import dataframe_to_rows
import warnings
from urllib3.exceptions import InsecureRequestWarning
warnings.simplefilter('ignore', InsecureRequestWarning)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7'
}
def tofind_banner():
banner = '''
_____ ______ _
|_ _| | ____| | |
| | ___ | |__ _ _ _ ___| |
| | / _ \ | __|| || \ | | / | |
| || (_) || | | || \| || (| | |
|_| \___/ |_| |_||_| \_| \___|_|
'''
print(banner)
def get_text(url):
#获取源代码
if not url.startswith('http://') and not url.startswith('https://'):
url = 'http://' + url
try:
s = requests.get(url, headers=headers, verify=False)
if str(s.status_code)[0] == '2': return s.text, url
else:
url = 'https://' + url[len('http://'):]
s = requests.get(url, headers=headers, verify=False)
if str(s.status_code)[0] == '2': return s.text, url
else: return '', url
except: return '', url
else:
s = requests.get(url, headers=headers, verify=False)
try:
if str(s.status_code)[0] == '2': return s.text, url
else: return '', url
except: return '', url
def get_text_api(source_code):
#获取源码中的api接口
# 使用正则表达式查找以"/"或'/'开头的字符串
pattern = r"['\"]((\/|\.\/)[^\n\r'\";]+)([\?;][^\n\r'\" ]*)?['\"]"
matches = re.findall(pattern, source_code)
apis = []
exclude_api = ['/', '//', '/favicon.ico', '/login', '/register', '/login.html', '/register.html'] # 排除的滥用接口
exclude_list = ['bootstrap', 'chosen', 'bootbox', 'awesome', 'animate', 'picnic', 'cirrus', 'iconfont', 'jquery', 'layui', 'swiper'] # 排除的插件库
for match in matches:
match = match[0] # 去除版本号js/css文件得版本号
# 仅当路径与 exclude_api 列表中的任意一个完全匹配时,才会被排除
if match and match not in exclude_api:
contains_excluded_str = False
for ex_str in exclude_list:
if ex_str in match:
contains_excluded_str = True
break
# 如果路径不包含任意一个 exclude_list 中的字符,则添加到 apis 列表中
if not contains_excluded_str:
apis.append(match)
# 去重
apis = list(set(apis))
return apis
def get_all_css_classes(url,text,apis):
#获取全部加载的css中所有的类名
css_links = []
exclude_list = ['bootstrap', 'chosen', 'bootbox', 'awesome', 'animate', 'picnic', 'cirrus', 'iconfont', 'jquery', 'layui', 'swiper'] # 排除的插件库
for href in apis:
if href and re.search(r'.css', href):
if not any(exclude in href for exclude in exclude_list):
css_links.append(requests.compat.urljoin(url, href))
pattern = r"https?://[^\s]*\.css"
matches = re.findall(pattern, text, re.DOTALL)
for match in matches:
# 排除包含插件库的链接
if not any(exclude in match for exclude in exclude_list):
css_links.append(match)
all_classes = set()
for css_link in css_links:
try:
css_content = requests.get(css_link, headers=headers, verify=False, timeout=10).text # 下载CSS
if css_content:
class_pattern = r'\.([\w\-]+)\s*\{'
matches = re.findall(class_pattern, css_content)
all_classes.update(matches)
except :
return [],css_links
return sorted(all_classes),css_links #返回css类名
def get_text_css_class(text):
#获取源码中的类名
soup = BeautifulSoup(text, 'html.parser')
# 找到所有的标签,并提取它们的 class 属性
all_classes = set() # 使用集合来存储唯一的类名,避免重复
for tag in soup.find_all(True): # 查找所有标签
classes = tag.get('class') # 获取标签的 class 属性值
if classes: # 如果存在 class 属性
all_classes.update(classes) # 将类名添加到集合中
return sorted(all_classes)
def get_power(text):
#获取power by/powered by后的内容
pattern = r'(?:powered by|power by)\s+(<a\s+[^>]*href="([^"]+)"[^>]*>|[^<>\s]+)'
match = re.search(pattern, text, re.IGNORECASE)
if match:
if match.group(2): # 如果匹配的是
return match.group(2) # 返回URL
else:
return match.group(1) # 返回单词或短语
return None
def fofa(base):
#通过fofa查询第一页最大条数为500的指纹数据
with open('config.json', 'r') as f:
config = json.load(f)
fofa_api_key = config['fofa_api_key']
if not fofa_api_key:
print("需要在config.json中配置Fofa Key")
exit()
url = f'https://fofa.info/api/v1/search/all?&key={fofa_api_key}&qbase64={base}&size=500'
s = requests.get(url, headers=headers)
return s.json()
def save_to_file(data, filename, filetype, size_value, url,fingerprint):
#数据保存到文件
if filetype == 'txt':
with open(filename, 'a+', encoding='utf-8') as f:
f.write(f"提取Url: {url}\n")
f.write(f"Size: {size_value}\n")
f.write(f"指纹:{fingerprint}\n")
for item in data:
f.write("%s\n" % item)
elif filetype == 'xlsx':
df_data = pd.DataFrame(data, columns=["URL", "IP", "Port"])
metadata = {"URL": f"{url}", "Size": size_value ,"fingerprint" : fingerprint}
file_exists = os.path.exists(filename)
if not file_exists:
with pd.ExcelWriter(filename, engine='openpyxl', mode='w') as writer:
df_metadata_header = pd.DataFrame(columns=["URL", "Size" ,"fingerprint"])
df_metadata_header.to_excel(writer, index=False, startrow=0, header=True)
df_metadata = pd.DataFrame([metadata])
df_metadata.to_excel(writer, index=False, header=False, startrow=1)
header_df = pd.DataFrame(columns=["URL", "IP", "Port"])
header_df.to_excel(writer, index=False, startrow=2, header=True)
df_data.to_excel(writer, index=False, header=False, startrow=3)
else:
with pd.ExcelWriter(filename, engine='openpyxl', mode='a', if_sheet_exists='overlay') as writer:
workbook = writer.book
sheet = workbook.active
df_metadata_header = pd.DataFrame(columns=["URL", "Size", "fingerprint"])
for r in dataframe_to_rows(df_metadata_header, index=False, header=True):
sheet.append(r)
df_metadata = pd.DataFrame([metadata])
for r in dataframe_to_rows(df_metadata, index=False, header=False):
sheet.append(r)
header_df = pd.DataFrame(columns=["URL", "IP", "Port"])
for r in dataframe_to_rows(header_df, index=False, header=True):
sheet.append(r)
for r in dataframe_to_rows(df_data, index=False, header=False):
sheet.append(r)
workbook.save(filename)
def Gather(url, param=None, output_file=None, execute_fofa=False, b=None, level=4):
# 核心函数
level = int(level)
start_url = url
s, url = get_text(url)
if s == '':
print(f"{start_url}访问不可达")
exit()
apis = get_text_api(s)
joined_apis = []
joined_classes = []
fingerprint = ''
filtered_apis = []
if len(apis) > 0:
pattern = r'\.(jpg|png|css|js|ico|svg|gif)'
other_apis = []
for api in apis:
if re.search(pattern, api): # 如果是静态资源文件
# 去除查询参数并添加到列表
filtered_apis.append(re.sub(r'(\?)[^&]*$', '', api))
else:
other_apis.append(api) # 保留其他接口的 URL
if len(other_apis) > 4:
random_other_apis = random.sample(other_apis, 4)
else:
random_other_apis = other_apis
if len(filtered_apis) > 2:
random_filtered_apis = random.sample(filtered_apis, 2)
else:
random_filtered_apis = filtered_apis
joined_apis = random_other_apis + random_filtered_apis
if len(joined_apis) > level+1 :
random_apis = random.sample(joined_apis, level+1)
joined_apis = '" && "'.join(random_apis)
else:
joined_apis = '" && "'.join(joined_apis)
else:
print("没有找到Api接口。")
css_classes,csslinks = get_all_css_classes(url, s, filtered_apis)
classes = set(get_text_css_class(s)).intersection(css_classes)
if len(classes) > 0:
classes = sorted(classes)
if len(classes) > level+1:
random_classes = random.sample(classes, level+1) # 挑选等级个数
joined_classes = '" && "'.join(random_classes)
else:
joined_classes = '" && "'.join(classes)
else:
if css_classes:
print(csslinks)
print("没有找到合适的类名。")
if b:
if joined_classes:
fingerprint = '"' + joined_classes + '"'
else:
print("blog网站没有合适的类,建议不要使用-b选项")
else:
if joined_classes and joined_apis:
fingerprint = '("' + joined_apis + '") || ("' + joined_classes + '")'
else:
if joined_apis:
fingerprint = '"' + joined_apis + '"'
elif joined_classes:
fingerprint = '"' + joined_classes + '"'
powerby_str = get_power(s)
if powerby_str:
fingerprint = '( ' + fingerprint + ' )' + ' && "' + powerby_str + '"'
if param:
fingerprint = '( ' + fingerprint + ' )' + ' && "' + param + '"'
print('Url:' + url)
if fingerprint:
print('构造的指纹如下' + fingerprint)
else:
print('没有构造出指纹信息')
if execute_fofa:
results = fofa(base64.b64encode(fingerprint.encode()).decode())
result_data = results.get('results', [])
size_value = results.get('size', 0) # 获取size值
if output_file:
filetype = output_file.split('.')[-1]
save_to_file(result_data, output_file, filetype, size_value,url,fingerprint)
else:
print(f"通过Fofa共搜索出{size_value}条数据")
for item in result_data:
print(item)
def Batch(url, param=None, output_file=None, execute_fofa=False, readfile=None, b=None, level=4):
#批量读取Url
if readfile:
with open(readfile, 'r') as f:
urls = f.readlines()
for url in urls:
url = url.strip()
Gather(url, param, output_file, execute_fofa, b, level)
else:
Gather(url, param, output_file, execute_fofa, b, level)
if __name__ == "__main__":
tofind_banner()
parser = argparse.ArgumentParser(description="依据css类 Api等来发现网站指纹,通过Fofa寻找同源码网站,使用Fofa查询之前要在json文件中添加Fofa key")
# 参数
parser.add_argument('-u', '--url', type=str, required=False, metavar='', help='网站Url')
parser.add_argument('-p', '--param', type=str, required=False, metavar='', help='输入要添加的参数,不要带问号、双引号这些特殊字符,要不然Fofa搜索时会报错的')
parser.add_argument('-o', '--output', type=str, required=False, metavar='', help='输出文件名,可以是txt或xlsx格式')
parser.add_argument('-r', '--readfile', type=str, required=False, metavar='', help='从txt文件中读取URL')
parser.add_argument('-l', '--level', type=str, required=False, metavar='',choices=['1', '2', '3', '4', '5'],default=4, help='指纹强度等级,默认4级,可选1、2、3来缩小强度等级,5来增强等级')
parser.add_argument('-f', '--fofa', action='store_true', help='是否执行Fofa搜索,不带-f选项只会输出框架指纹')
parser.add_argument('-b', '--blog', action='store_true', help='是否是blog或首页网站,不带-b选项代表是登录界面,没有杂乱的Api')
args = parser.parse_args()
if args.output:
valid_formats = ['.txt', '.xlsx']
file_format = '.' + args.output.split('.')[-1].lower()
if file_format not in valid_formats:
print("输出文件格式必须是txt或xlsx")
exit()
if os.path.exists(args.output):
if args.output.endswith('.xlsx'):
wb = Workbook()
wb.save(args.output)
else:
with open(args.output, 'w') as file:
pass
file.close()
Batch(args.url, args.param, args.output, args.fofa, args.readfile, args.blog, args.level)
同源测试
https://jwxt.lcu.edu.cn/jwglxt/xtgl/login_slogin.html
python3 ToFind.py -u https://jwxt.lcu.edu.cn/jwglxt/xtgl/login_slogin.html -f | more
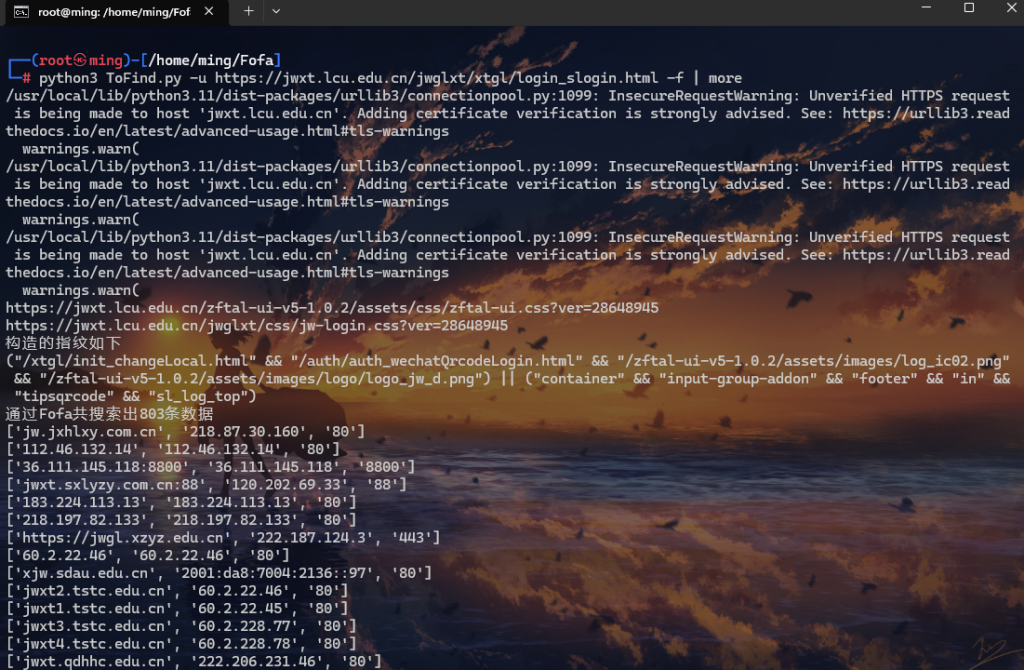
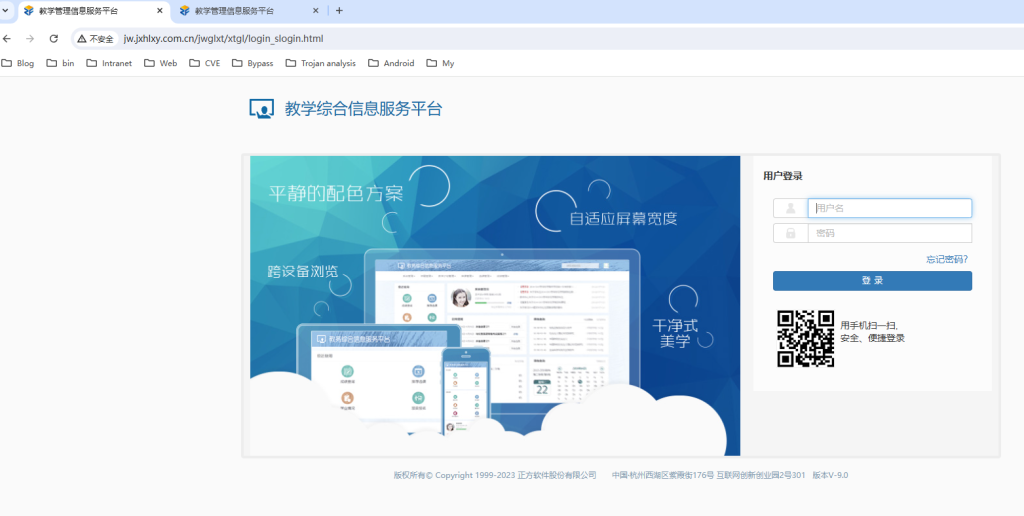
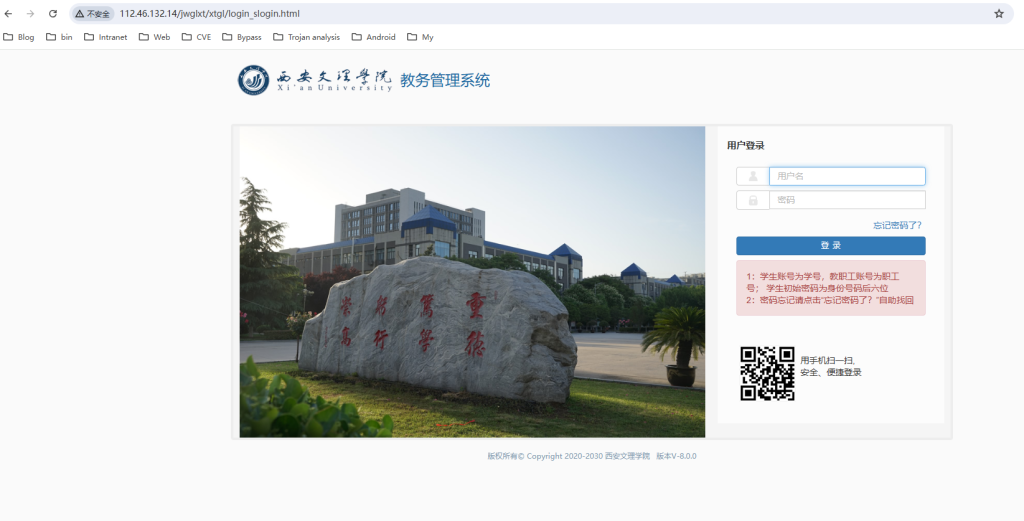
http://speak13.com:81/
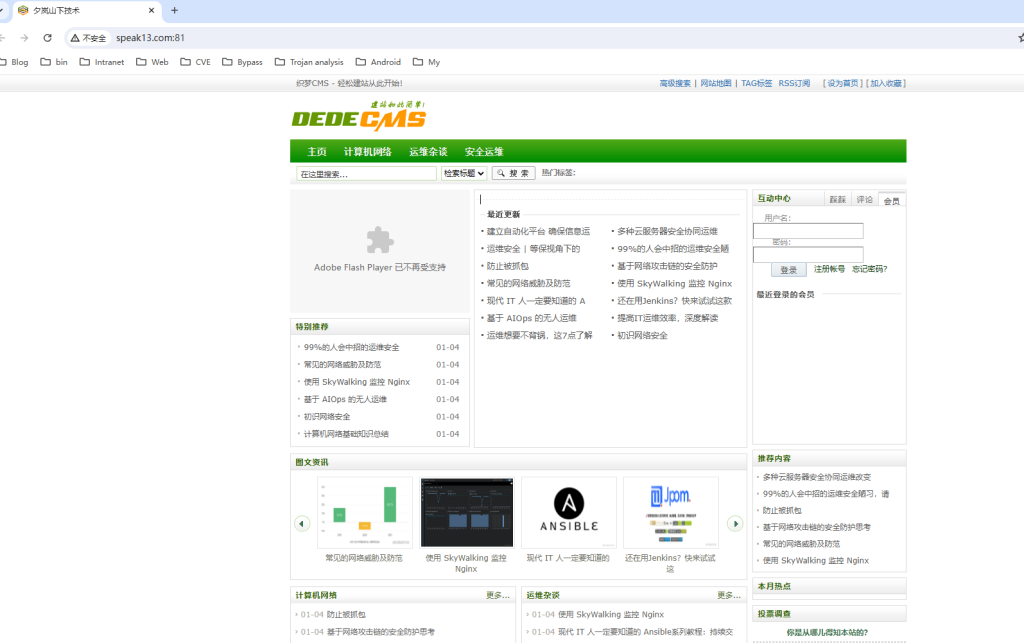
python3 ToFind.py -u http://speak13.com:81/ -f | more
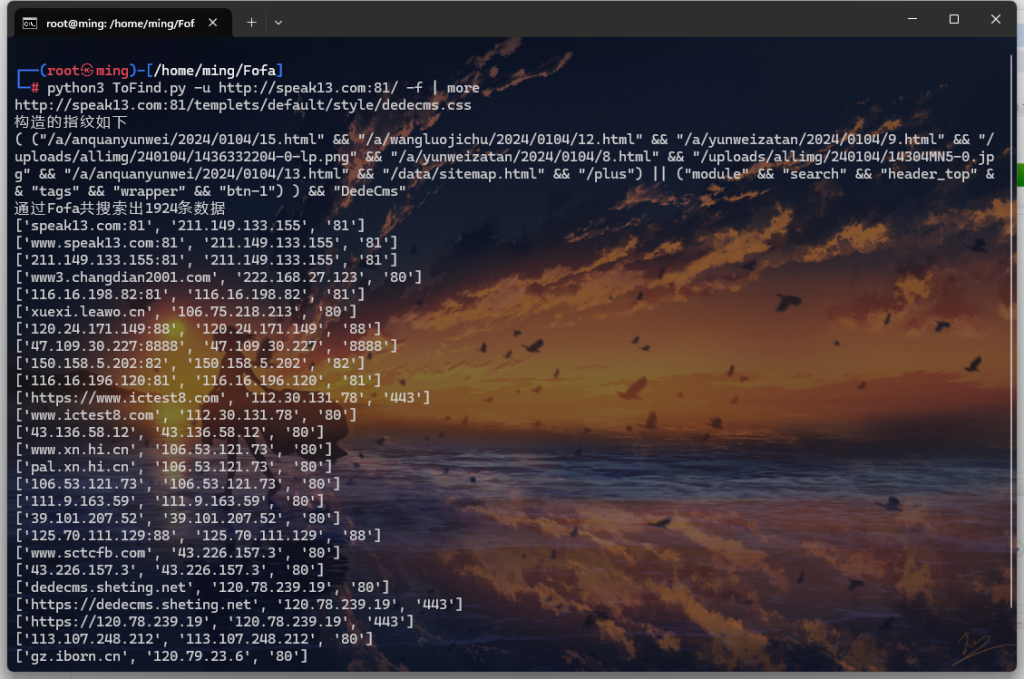
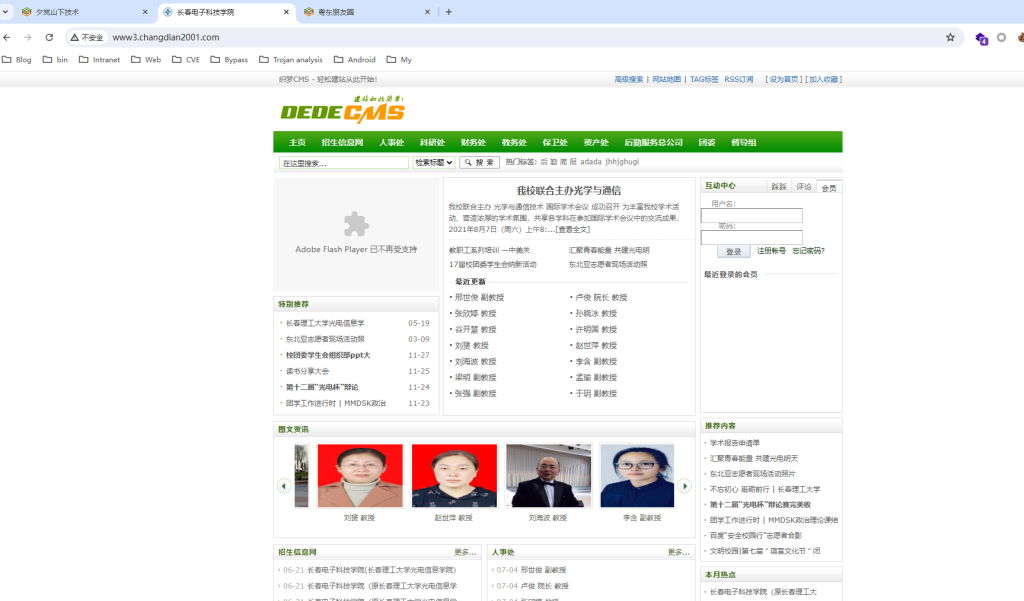
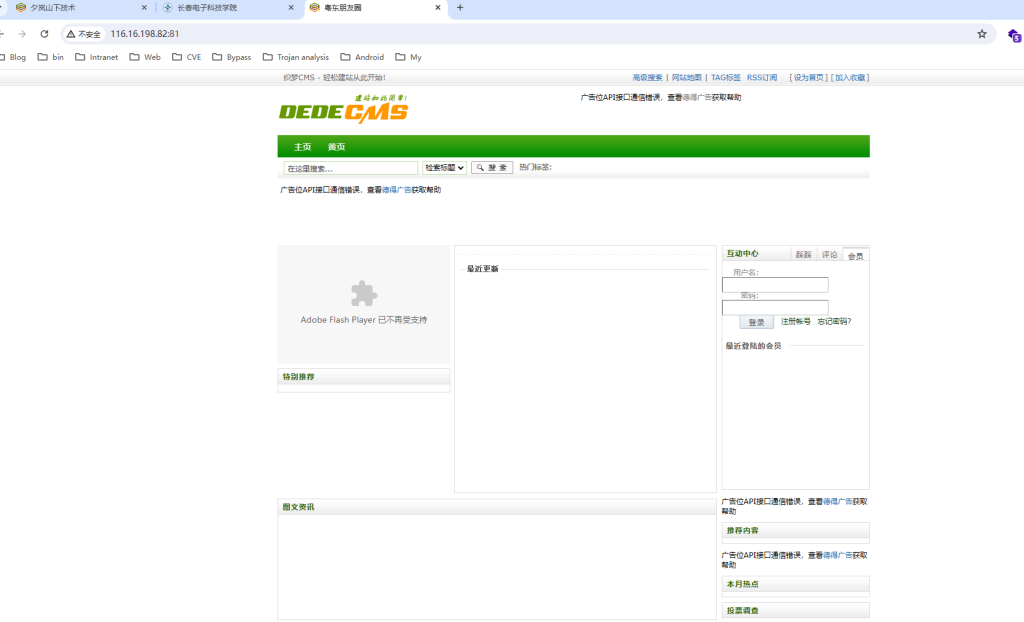
(hexo)
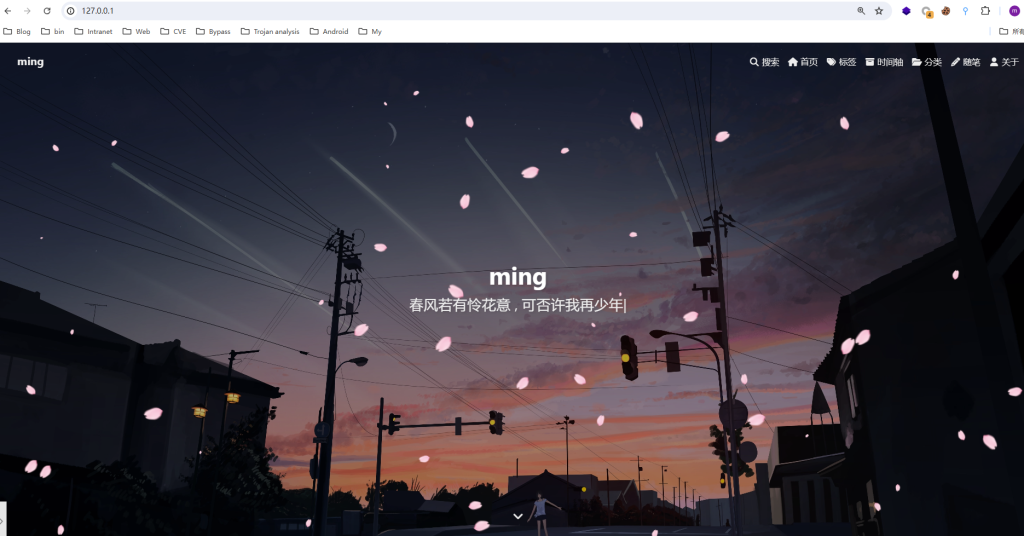
python ToFind.py -u http://localhost:4000/ -f -b | more